-
-
 A new WearWear OS 7: New features, eligible smartwatches, and everything you need to know
A new WearWear OS 7: New features, eligible smartwatches, and everything you need to know -
 Remixed videos'Video Remix' in Google Photos reimagines reality into your ideal scenario
Remixed videos'Video Remix' in Google Photos reimagines reality into your ideal scenario -
 Just takes a promptMeta's Muse Image can use public Instagram profiles for AI creations
Just takes a promptMeta's Muse Image can use public Instagram profiles for AI creations -
 About timeMeta's smart glasses will now disable the camera if you tamper with the privacy light
About timeMeta's smart glasses will now disable the camera if you tamper with the privacy light -
 Get creativePixel Studio is dead, but there are still a few ways you can make fun stickers on your Pixel phone. Here's how
Get creativePixel Studio is dead, but there are still a few ways you can make fun stickers on your Pixel phone. Here's how -
 Quiet changeYour Android phone backup now counts against your Google storage — but the impact is smaller than you think
Quiet changeYour Android phone backup now counts against your Google storage — but the impact is smaller than you think -
 AC PollsLet us know: Are you Team Google, Team Android, or both?
AC PollsLet us know: Are you Team Google, Team Android, or both?
-







-
-
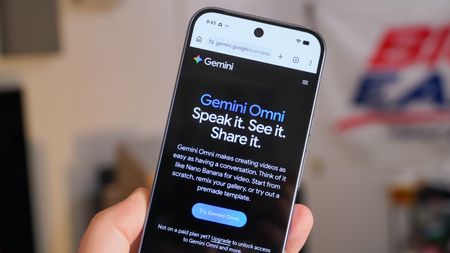 Google AIGemini Omni is 'like Nano Banana for video' and I couldn't believe the results
Google AIGemini Omni is 'like Nano Banana for video' and I couldn't believe the results -
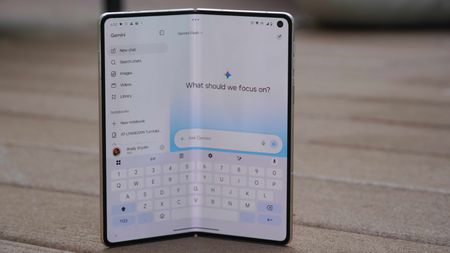 Lively Gemini LiveI barely use Gemini's default chatbot after trying the new Gemini Live interface
Lively Gemini LiveI barely use Gemini's default chatbot after trying the new Gemini Live interface -
 Gemini is on the wayGoogle's AI browsing assistant, Gemini in Chrome, is headed to even more users and places
Gemini is on the wayGoogle's AI browsing assistant, Gemini in Chrome, is headed to even more users and places -
 Google AIGoogle Gemini AI: Gemini 3.5 Flash, Nano Banana, Live, best features, linked apps, and more
Google AIGoogle Gemini AI: Gemini 3.5 Flash, Nano Banana, Live, best features, linked apps, and more -
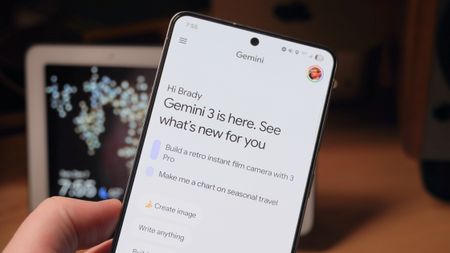 Feedback heardComplaints worked: Google is already addressing Gemini's new usage limits2 Comments
Feedback heardComplaints worked: Google is already addressing Gemini's new usage limits2 Comments -
 AI backlash growsFormer Google CEO Eric Schmidt booed after AI remarks at the University of Arizona2 Comments
AI backlash growsFormer Google CEO Eric Schmidt booed after AI remarks at the University of Arizona2 Comments -
 Quiet downgradeThe Google AI Pro plan just got a quiet downgrade, here is the new deal2 Comments
Quiet downgradeThe Google AI Pro plan just got a quiet downgrade, here is the new deal2 Comments -
 Gemini takeover5 important Gemini updates from Google I/O that could genuinely save you time
Gemini takeover5 important Gemini updates from Google I/O that could genuinely save you time -
 Genie "magic"Dreaming of Project Genie? Google I/O unveils 'Street View,' putting imaginary worlds into ours
Genie "magic"Dreaming of Project Genie? Google I/O unveils 'Street View,' putting imaginary worlds into ours
-









-
-
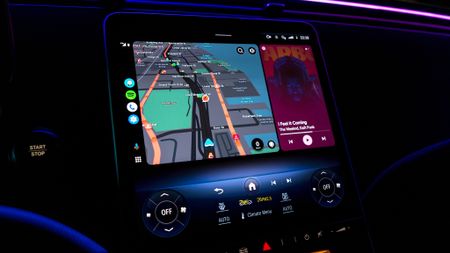 Auto vs. AutomotiveAndroid Auto vs. Android Automotive: 5 major things that separate the two
Auto vs. AutomotiveAndroid Auto vs. Android Automotive: 5 major things that separate the two -
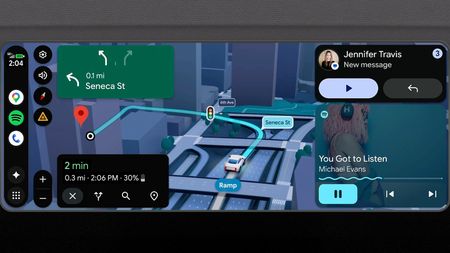 Take a driveAndroid Auto gets a fresh take on Google Maps navigation, teases more Gemini at the Android Show
Take a driveAndroid Auto gets a fresh take on Google Maps navigation, teases more Gemini at the Android Show -
 Smarter driving5 Android Auto settings I always change on any new Android phone
Smarter driving5 Android Auto settings I always change on any new Android phone -
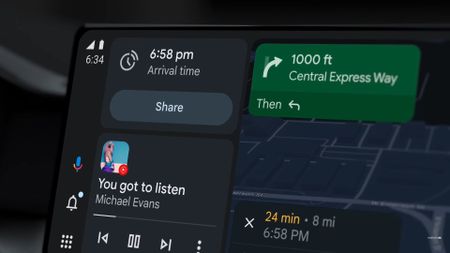 Android Auto bug is making the signal icon vanish for some users2 Comments
Android Auto bug is making the signal icon vanish for some users2 Comments -
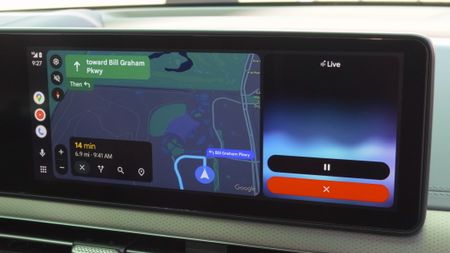 Finally fixedAndroid's Driving Mode is finally smarter about when it turns on3 Comments
Finally fixedAndroid's Driving Mode is finally smarter about when it turns on3 Comments -
 Where'd it go?Something's missing: Android Auto users report a jarring bug in Google Maps
Where'd it go?Something's missing: Android Auto users report a jarring bug in Google Maps -
It might finally happenAndroid Auto may finally let you cast media from your phone
-
Gemini-fiedGemini transforms Android Auto with new AI features for a smarter drive
-
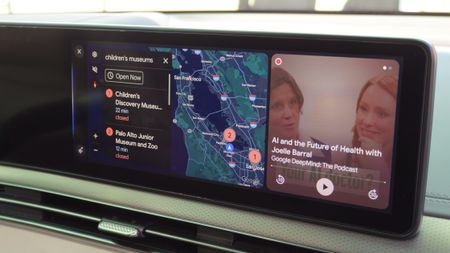 Bye, Assistant!Gemini for Android Auto is starting to replace Google Assistant
Bye, Assistant!Gemini for Android Auto is starting to replace Google Assistant
-







-
-
Get creativePixel Studio is dead, but there are still a few ways you can make fun stickers on your Pixel phone. Here's how
-
Quiet changeYour Android phone backup now counts against your Google storage — but the impact is smaller than you think
-
AC PollsLet us know: Are you Team Google, Team Android, or both?
-
 It's been one weekPlatform Stability reached: Android 17 QPR1 Beta 6 is here for Pixels, quickly after Beta 5
It's been one weekPlatform Stability reached: Android 17 QPR1 Beta 6 is here for Pixels, quickly after Beta 5 -
 DND, I'm gamingAndroid 17 'sneak peek' at a foldable gaming mode has my attention—and then some
DND, I'm gamingAndroid 17 'sneak peek' at a foldable gaming mode has my attention—and then some -
 Begone bugs!Pixel testers are getting Android 17 QPR1 Beta 5: this is what's important
Begone bugs!Pixel testers are getting Android 17 QPR1 Beta 5: this is what's important -
 Quiet upgradeAndroid 17 brings a surprisingly big upgrade for wireless earbuds
Quiet upgradeAndroid 17 brings a surprisingly big upgrade for wireless earbuds -
 Hidden namesI changed one Android 17 setting and made my Pixel home screen so much cleaner
Hidden namesI changed one Android 17 setting and made my Pixel home screen so much cleaner -
 Hold off on the updateAndroid 17 is off to a rough start with new Pixel touchscreen complaints9 Comments
Hold off on the updateAndroid 17 is off to a rough start with new Pixel touchscreen complaints9 Comments
-






-
-
 Gmail inside ProtonThis secure email service just gave me a real reason to ditch Gmail
Gmail inside ProtonThis secure email service just gave me a real reason to ditch Gmail -
A fresh coat of paintGoogle's new gradient icons for Gmail, Calendar, Drive and more are finally rolling out
-
 That's a big cutGoogle may be cutting free Gmail storage for new accounts down to 5GB
That's a big cutGoogle may be cutting free Gmail storage for new accounts down to 5GB -
 Useful parroting?Gmail's 'Help me write' can now mimic how you speak to create emails for you
Useful parroting?Gmail's 'Help me write' can now mimic how you speak to create emails for you -
New address, same inboxI changed my embarrassing Gmail username without losing anything, and you can too2 Comments
-
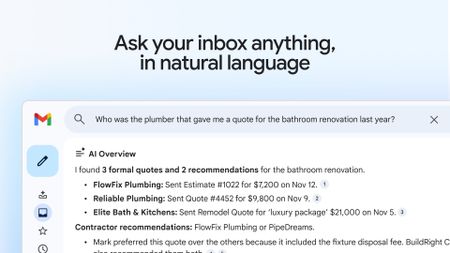 That's a steep priceGmail's new AI Inbox is here, but it'll cost you $250 a month
That's a steep priceGmail's new AI Inbox is here, but it'll cost you $250 a month -
 Gemini takes overGmail is getting a new AI inbox as Google brings Gemini front and center2 Comments
Gemini takes overGmail is getting a new AI inbox as Google brings Gemini front and center2 Comments -
A long-awaited featureGmail might finally let you switch to a new address without starting over
-
Get a previewGmail gives Android users a window into email attachments with this update
-





-
-
 Bye, AssistantGoogle Assistant could shut down for Android Auto in March 2026
Bye, AssistantGoogle Assistant could shut down for Android Auto in March 2026 -
 New look!Google's song search evolves with a modern Gemini-inspired UI on Android
New look!Google's song search evolves with a modern Gemini-inspired UI on Android -
 New look!Google's voice and song search gets a major overhaul on Android after years
New look!Google's voice and song search gets a major overhaul on Android after years -
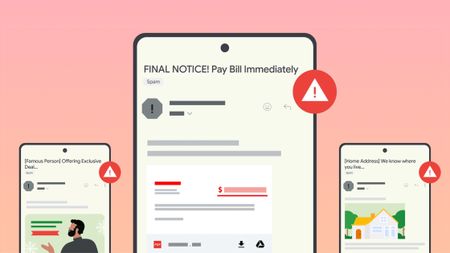 Stay in the knowGoogle introduces new tools to help users fight against evolving phishing scams effectively
Stay in the knowGoogle introduces new tools to help users fight against evolving phishing scams effectively -
 Google OutageGoogle, Gmail, and Meet hit by widespread outage, causing login issues
Google OutageGoogle, Gmail, and Meet hit by widespread outage, causing login issues -
 New voicesGoogle is spicing up its voice list on Search, according to a new leak
New voicesGoogle is spicing up its voice list on Search, according to a new leak -
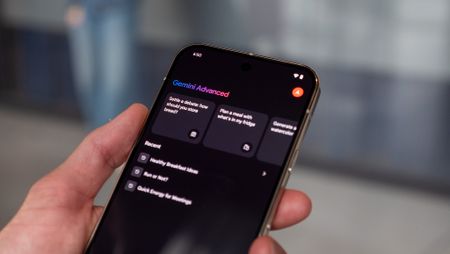 New Google AI plansNew Google AI Pro and $249/month Ultra subscription announced at I/O
New Google AI plansNew Google AI Pro and $249/month Ultra subscription announced at I/O -
Easy-peesyGoogle app on iOS gets a new feature that will 'Simplify' text online
-
 ByeGoogle officially killed Driving Mode after stripping most of its features in 2024
ByeGoogle officially killed Driving Mode after stripping most of its features in 2024
-








-
-
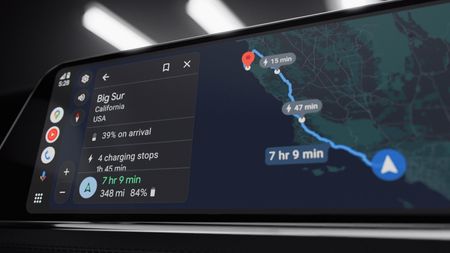 Don't stressGet in: Android Auto EVs see AI battery predictions in Google Maps for stress-free plans
Don't stressGet in: Android Auto EVs see AI battery predictions in Google Maps for stress-free plans -
 It's just like new'Immersive Navigation' in Google Maps is like opening a new app for the modern era of driving
It's just like new'Immersive Navigation' in Google Maps is like opening a new app for the modern era of driving -
Limiting features?Google Maps might keep things from you if you don't sign in to an account
-
 Test runGoogle Maps might get a trial space for new features, and 'Ask Maps' could headline
Test runGoogle Maps might get a trial space for new features, and 'Ask Maps' could headline -
 Out on a walkMy walks just got a lot better, as Google says 'Gemini in Navigation' supports more
Out on a walkMy walks just got a lot better, as Google says 'Gemini in Navigation' supports more -
 Better battery lifeHow to enable and use Google Maps power saving mode
Better battery lifeHow to enable and use Google Maps power saving mode -
Let's go thereGoogle Maps gets a major upgrade with Gemini for smooth navigation on Android and iOS
-
Let's go thereGoogle Maps gets a Gemini boost to help you navigate the roads like a pro
-
 Double RainbowHere's what the redesigned Google Photos and Maps icons look like
Double RainbowHere's what the redesigned Google Photos and Maps icons look like
-






-
-
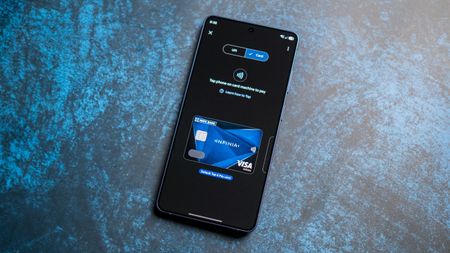 How ToThis is the best Google Pay feature you're not using in India
How ToThis is the best Google Pay feature you're not using in India -
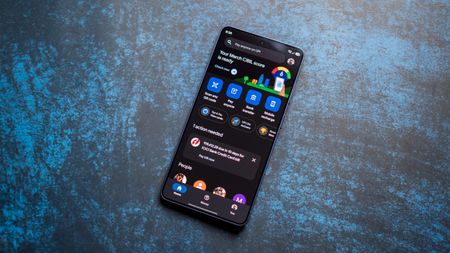 How ToI used this hidden Google Pay feature to automate credit card bill payments
How ToI used this hidden Google Pay feature to automate credit card bill payments -
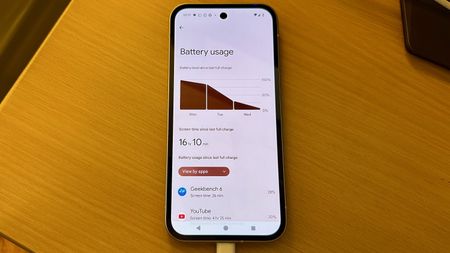 No more drainAndroid’s next update is finally addressing your phone’s biggest battery hogs
No more drainAndroid’s next update is finally addressing your phone’s biggest battery hogs -
 On TimeGoogle Wallet is helping Android users effortlessly catch their plane or train
On TimeGoogle Wallet is helping Android users effortlessly catch their plane or train -
 Quick TapsGoogle Pay's fresh updates will unlock better shopping rewards for Chrome users
Quick TapsGoogle Pay's fresh updates will unlock better shopping rewards for Chrome users -
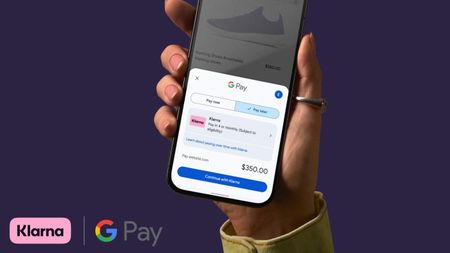 Pay Your WayAndroid users get another option to pay later with Klarna on Google Pay
Pay Your WayAndroid users get another option to pay later with Klarna on Google Pay -
 Easier accessGoogle Wallet brings digital ID support to UK, more US states
Easier accessGoogle Wallet brings digital ID support to UK, more US states -
Now arriving at...Google Wallet brings real-time train status alerts to Android, and teases I/O 2025
-
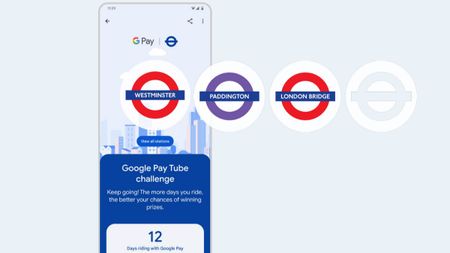 Next stop is...Londoners can join the Google Pay 'Tube Challenge' for badges and city lore
Next stop is...Londoners can join the Google Pay 'Tube Challenge' for badges and city lore
-








-
-
 Keeping you awareWarnings about removed or unsupported Play Store apps could head to Android
Keeping you awareWarnings about removed or unsupported Play Store apps could head to Android -
 Play gets smarterGoogle Play is getting a huge AI upgrade with Ask Play and Play Shorts
Play gets smarterGoogle Play is getting a huge AI upgrade with Ask Play and Play Shorts -
 Create appsThis Google AI tool can now build Android apps from text prompts
Create appsThis Google AI tool can now build Android apps from text prompts -
 It's a problemGoogle puts apps that'll drain your battery on blast in updated Play Store listings
It's a problemGoogle puts apps that'll drain your battery on blast in updated Play Store listings -
A downgrade to downgradingGoogle just made uninstalling system app updates more complicated
-
Free cashHere's when Google Play Store users will get an automatic cash settlement payout3 Comments
-
 You win!Focus Friend and Pokémon TCG Pocket shine in Google Play's Best of 2025 awards
You win!Focus Friend and Pokémon TCG Pocket shine in Google Play's Best of 2025 awards -
Find it fasterGoogle Play enhances search with new 'Where to watch' streaming feature
-
 No more siftingGoogle's upcoming review search feature might soon help you save time on the Play Store
No more siftingGoogle's upcoming review search feature might soon help you save time on the Play Store
-






-
-
Just takes a promptMeta's Muse Image can use public Instagram profiles for AI creations
-
About timeMeta's smart glasses will now disable the camera if you tamper with the privacy light
-
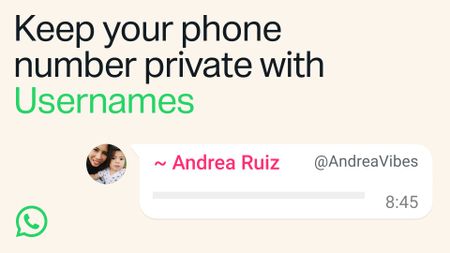 What's your username?You can reserve your WhatsApp username this week to keep your number private
What's your username?You can reserve your WhatsApp username this week to keep your number private -
 HonorIn honor of our heroes, Meta says it's donating Ray-Ban glasses to legally blind veterans
HonorIn honor of our heroes, Meta says it's donating Ray-Ban glasses to legally blind veterans -
 Aided by AIMeta AI was used to steal many high-profile Instagram accounts, and people want answers
Aided by AIMeta AI was used to steal many high-profile Instagram accounts, and people want answers -
 Subscriptions aplentyMeta unveils app subscriptions: 'Plus' plans precede 'Meta One' tests for AI and creators
Subscriptions aplentyMeta unveils app subscriptions: 'Plus' plans precede 'Meta One' tests for AI and creators -
 Protecting privacyI protect my privacy while using Meta smart glasses with these 3 settings — and you can too
Protecting privacyI protect my privacy while using Meta smart glasses with these 3 settings — and you can too -
 Another chunk... goneMeta chops 8,000 in May layoff spree, and it's only getting worse
Another chunk... goneMeta chops 8,000 in May layoff spree, and it's only getting worse -
 AI everywhereMeta's Muse Spark arrives on AI Glasses Gen 1, Ray-Ban Display waits for now
AI everywhereMeta's Muse Spark arrives on AI Glasses Gen 1, Ray-Ban Display waits for now
-







-
-
 Spotify drives engagement the right way, expands into 'Fitness' with Peloton
Spotify drives engagement the right way, expands into 'Fitness' with Peloton -
 A worthy upgradeSpotify looks brand new on tablets with a design rework that makes total sense
A worthy upgradeSpotify looks brand new on tablets with a design rework that makes total sense -
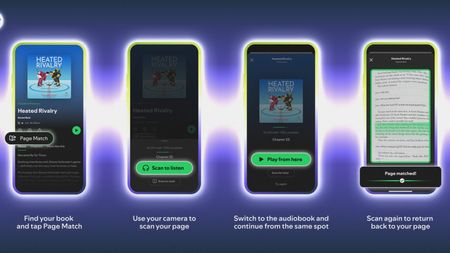 Reading is goodSpotify, Bookshop expand to US, and 'Page Match' gets huge language support
Reading is goodSpotify, Bookshop expand to US, and 'Page Match' gets huge language support -
 Podcasts this timePodcasts meet Spotify's Prompted Playlists for curious Premium US beta testers
Podcasts this timePodcasts meet Spotify's Prompted Playlists for curious Premium US beta testers -
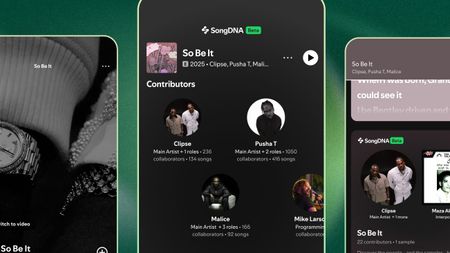 A vast webIt's in the SongDNA: an 'immersive' Spotify test that lets you discover everyone involved
A vast webIt's in the SongDNA: an 'immersive' Spotify test that lets you discover everyone involved -
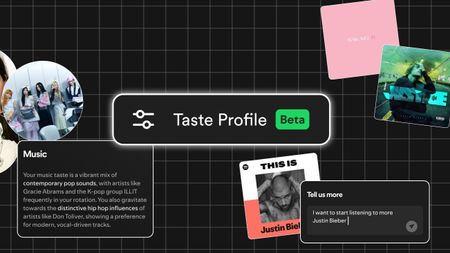 Your tasteAll to your liking: Spotify's 'Taste Profile' beta puts you in charge of the music you find
Your tasteAll to your liking: Spotify's 'Taste Profile' beta puts you in charge of the music you find -
 InspiredSpotify's 'About the Song' beta lets you into the stories behind the artist's creation
InspiredSpotify's 'About the Song' beta lets you into the stories behind the artist's creation -
 Turn the pageI'll never stop reading with Spotify, Bookshop's partnership and 'Page Match' on Android
Turn the pageI'll never stop reading with Spotify, Bookshop's partnership and 'Page Match' on Android -
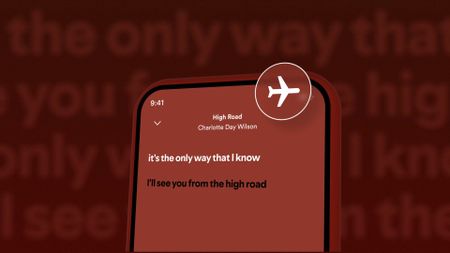 I can show you the...This Spotify update lets us take our lyrics offline, and there's more for users globally
I can show you the...This Spotify update lets us take our lyrics offline, and there's more for users globally
-









-
-
 X is down againX faces major outage as 78K users report disruption this morning
X is down againX faces major outage as 78K users report disruption this morning -
Where are you?X's new 'transparent' location labels for accounts have people questioning everything
-
 Partial outageFacing trouble logging into X? You're not alone — here’s the scoop!
Partial outageFacing trouble logging into X? You're not alone — here’s the scoop! -
 Twitter is downIt wasn't just you — X (Twitter) resolved a major outage today
Twitter is downIt wasn't just you — X (Twitter) resolved a major outage today -
 Whistleblower calls out Twitter for spambots and mishandling user data
Whistleblower calls out Twitter for spambots and mishandling user data -
 What is free speech?
What is free speech? -
 Twitter makes it easier to search for Communities on the web
Twitter makes it easier to search for Communities on the web -
 Massive Twitter outage ends after about 90 minutes
Massive Twitter outage ends after about 90 minutes -
 House committee summons Meta, Alphabet, Twitter and Reddit over Capitol riot
House committee summons Meta, Alphabet, Twitter and Reddit over Capitol riot
-








-
-
A new WearWear OS 7: New features, eligible smartwatches, and everything you need to know
-
 Wear OS 7 updatesWear OS 7 is here with better battery life and a massive smart home upgrade
Wear OS 7 updatesWear OS 7 is here with better battery life and a massive smart home upgrade -
 Wear thisThe best Wear OS watch 2026
Wear thisThe best Wear OS watch 2026 -
 Wear OS updateWear OS 7 officially revealed: Here are the biggest new features
Wear OS updateWear OS 7 officially revealed: Here are the biggest new features -
 About timeGoogle just announced Wear OS 6.1, and it adds a time zone feature I've wanted for years
About timeGoogle just announced Wear OS 6.1, and it adds a time zone feature I've wanted for years -
 A proper upgradeSpotify on Wear OS just got a big redesign that makes it much easier to use
A proper upgradeSpotify on Wear OS just got a big redesign that makes it much easier to use -
 Standalone protectionWear OS can now send life-saving earthquake alerts without your phone
Standalone protectionWear OS can now send life-saving earthquake alerts without your phone -
 Visual messA major Wear OS 6 bug is ruining custom watch faces on Pixel and Galaxy Watches
Visual messA major Wear OS 6 bug is ruining custom watch faces on Pixel and Galaxy Watches -
 Wearables WeeklyWhat I expect and want to see from Android smartwatches in 2026
Wearables WeeklyWhat I expect and want to see from Android smartwatches in 2026
-








-
-
 TIkTok-styleYouTube Shorts just borrowed more of TikTok's best tricks
TIkTok-styleYouTube Shorts just borrowed more of TikTok's best tricks -
 More AI slopGoogle's new YouTube AI tools could make AI slop impossible to escape
More AI slopGoogle's new YouTube AI tools could make AI slop impossible to escape -
 The Premium pressureYouTube on mobile makes livestream ads way less annoying, but there's a caveat
The Premium pressureYouTube on mobile makes livestream ads way less annoying, but there's a caveat -
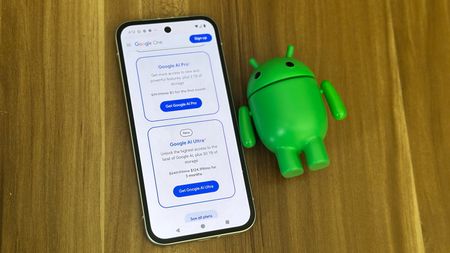 Half off YouTubeYou can now get YouTube Premium for half price with Google AI Pro
Half off YouTubeYou can now get YouTube Premium for half price with Google AI Pro -
 Shorts, gone (almost)YouTube now lets you turn off Shorts
Shorts, gone (almost)YouTube now lets you turn off Shorts -
 Premium gets pricierYouTube Premium just got a price hike, and it's not a small one3 Comments
Premium gets pricierYouTube Premium just got a price hike, and it's not a small one3 Comments -
Trying something newYouTube tests a couple of speedy, 'on-the-go' features for busy Android viewers
-
 Sort of supportedYouTube now works with Android Auto, but not in the way you'd expect
Sort of supportedYouTube now works with Android Auto, but not in the way you'd expect -
 Check it outDiscovering YouTube videos with 'Previews' is a change it wants to see if you like
Check it outDiscovering YouTube videos with 'Previews' is a change it wants to see if you like
-







